2X your redshift speed with sortkeys and distkeys
- Blog
- Developer experience (DevX)
The new guy in Town
Like a lot of folks in the data community, we’ve been impressed with Redshift, Amazon’s new distributed database. Yet at first, we couldn’t figure out why performance was so variable on seemingly-simple queries.
The key is carefully planning each table’s sort key and distribution key.
A table’s distkey is the column on which it’s distributed to each node. Rows with the same value in this column are guaranteed to be on the same node.
A table’s sortkey is the column by which it’s sorted within each node.
A naive table
Our 1B-row activity table is set up this way:
create table activity (
id integer primary key,
created_at_date date,
device varchar(30)
);A common query is: How much activity was there on each day, split by device?
select created_at_date, device, count(1)
from activity
group by created_at_date, device
order by created_at_date;This gives you a chart like this:
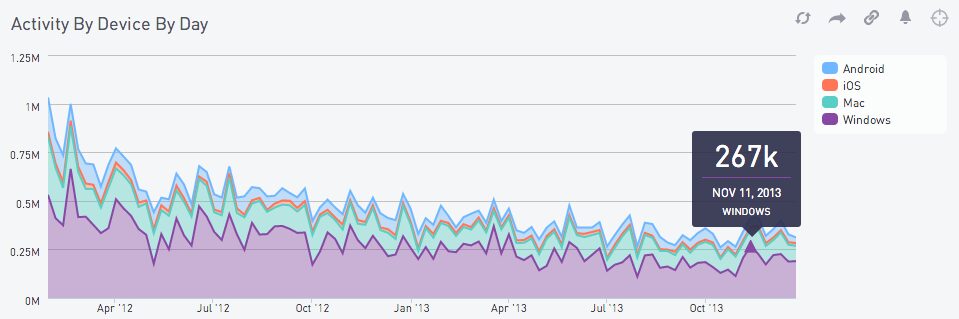
On a cluster with 8 dw2.large nodes, this query takes 10 seconds. To understand why, let’s turn to Redshift’s handy CPU Utilization graph:
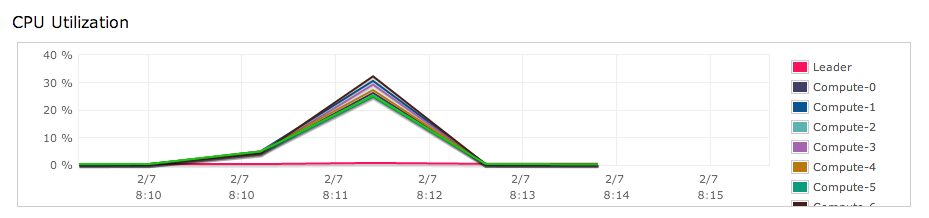
That is a ton of CPU usage for a simple count query!
The problem is our table has no sortkey and no distkey. This means Redshift has distributed our rows to each node round-robin as they’re created, and the nodes aren’t sorted at all.
As a result, each node must maintain thousands of counters — one for each (date, device) pair. Each time it counts a row, it looks up the right counter and increments it. On top of that, the leader must aggregate all the counters. This is where all of our CPU time is going.
Smarter distribution and sorting
Let’s remake our table with a simple, intentional sortkey and distkey:
create table activity (
id integer primary key,
created_at_date date sortkey distkey,
device varchar(30)
);Now our table will be distributed according to created_at_date, and each node will be sorted by created_at_date. The same query runs on this table in 8 seconds, a solid 20% improvement.
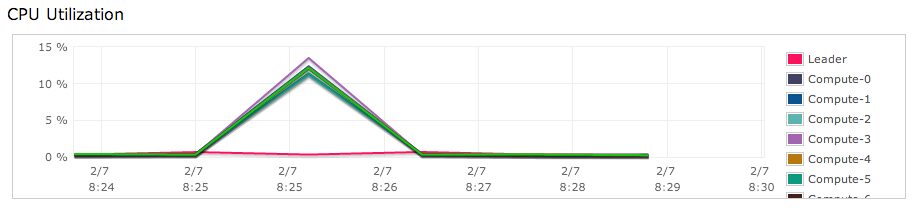
Because each node is sorted by created_at_date, it only needs one counter per device. As soon as the node is done iterating over each date, the values in each device counter are written out to the result, because the node knows it will never see that date again.
Even better, because dates are unique to each node, the leader doesn’t have to do any math over the results. It can just concatenate them and send them back.
Our approach is validated by lower CPU usage across the board:
Getting Really Specific
But what if there were a way to only require one counter? Fortunately Redshift allows multi-key sorting:
create table activity (
id integer primary key,
created_at_date distkey,
device varchar(30)
)
sortkey (created_at_date, device);Our query runs on this table in 5 seconds, a 38% improvement over the previous table, and a 2X improvement from the naive query!
Once again, the CPU chart will show us how much work is required:
Our query runs on this table in 5 seconds, a 38% improvement over the previous table, and a 2X improvement from the naive query!
Once again, the CPU chart will show us how much work is required:
Keep exploring




Subscribe to the Sisense newsletter
Get monthly insights on building smarter products with AI-powered analytics, from industry trends to real Sisense use cases.