7 signs you’re dealing with complex data
- Blog
- BI Best Practices
We talk a lot about complex data and the challenges and opportunities it poses for your business intelligence. But what is complex data? And how can you tell if your organization’s current data can be considered “complex,” or will be…
We talk a lot about complex data and the challenges and opportunities it poses for your business intelligence. But what is complex data? And how can you tell if your organization’s current data can be considered “complex,” or will be so in the near future? This post will address these questions.
Why does this matter?
The complexity of your data is likely to indicate the level of difficulty you’ll face when trying to translate it into business value – a complex data set is typically more difficult to prepare and analyze than simple data, and often will require a different set of BI tools to do so. Complex data necessitates additional work to prepare and model the data before it is “ripe” for analysis and visualization. Hence it is important to understand the current complexity of your data, and its potential complexity in the future, to assess whether your business intelligence project will be up to the task.
The simple test: big or disparate data
In high-level terms, there are two basic indications that your data might be considered complex:
- Your data is “big”: We’ve placed the word big in quotes because of the seemingly infinite meanings of the term “big data.” However, the fact of the matter remains that dealing with larger amounts of data poses a challenge in terms of the computational resources needed to process massive datasets, as well as the difficulty of separating the wheat from the chaff, i.e. distinguishing between signal and noise amid a huge deposit of raw information.
- Your data is coming from many disparate sources: Multiple data sources can often mean messy data, or simply multiple data sets that follow a different internal logic or structure. Data must, therefore, be transformed, or consolidated into a central repository in order to ensure your sources are all speaking the same language.
These could be considered the two (alternate) initial warning signs: If you’re dealing with big or disparate data, you should begin to think of your data as complex. But to delve a bit deeper, here are seven more specific indicators of the complexity of your organization’s data, which in effect are a more detailed version of the above mentioned two.
(Note that there are some similarities, and one certainly does not exclude the other – on the contrary, dispersed data can often mean a variety of data structures and types, for example.)
7 factors to determine your data’s complexity

1. Structure
Data from different sources, or even different tables from within the same source, could often refer to the same information but be structured entirely differently. For example, imagine your HR department has three different spreadsheets, one for employees’ personal details, another for their role and salary, a third for their qualifications, etc. – whereas your finance department records the same information in a single table, along with insurance, benefits, and other costs. Additionally, in some of these tables employees might be mentioned by their full name, in others by initial, or some combination of the two.
To efficiently use data from all these different tables, without losing or duplicating information, requires data modeling and preparation work. This is the simplest use case: working with unstructured data sources (such as NoSQL databases) can further complicate matters, as initially these have no schema in place.
2. Size
Again returning to the murky concept of “big data,” the amount of data you collect can affect the types of software or hardware you need to analyze it. This can be measured either in raw size: gigabytes, terabytes or petabytes – the larger the data grows, the more likely it is to “choke” popular in-memory databases that rely on shifting compressed data into your server’s RAM. Additional considerations include tall data – tables that contain many rows (Excel, arguably the most commonly used data analysis tool, is limited to 1048576 rows), or wide data – tables that contain many columns. You’ll find that the tools and methods you use to analyze 100,000 rows are significantly different than those needed to analyze 1 billion.
3. Detail
The level of granularity in which you wish to explore the data. When creating a dashboard or report, presenting summarized or aggregated data is often easier than giving end-users the ability to drill into every last detail – however, this is a tradeoff that comes at the price of limiting the possible depth of analysis and data discovery. Creating a BI system that enables granular drill-downs means having to process larger amounts of data on an ad-hoc basis (without relying on predefined queries, aggregations or summary tables).
4. Query language
Different data sources speak different languages: while SQL is the primary means of extracting data from common sources and RDBMS, when using a third party platform you will often need to connect to it via its own API and syntax, and to understand the internal data model and protocols used to access this data. Your BI tool needs to be flexible enough to allow for this type of native connectivity to said data source, either via built-in connectors or API access, or else you will find yourself having to repeat a cumbersome process of exporting the data to a spreadsheet SQL database data warehouse and then pulling it into your business intelligence software from there, making your analysis cumbersome.
5. Data type
Working with mostly numeric, operational data stored in tabular form is one thing, but massive and unstructured machine data is another thing entirely, as is a text-heavy data set stored in MongoDB, not to mention video and audio recordings. Different types of data have different rules, and finding a way to forge a single source of truth from all of them is essential in order to base your business decisions on an integrated view of all your organization’s data.
6. Dispersed data
Simply put this is data stored in multiple locations. For example, different departments inside the organization, on-premises or in the cloud (either in purchased storage or via cloud applications), external data originating from clients or suppliers, etc. This data is both more difficult to gather (simply because of the amount of stakeholders who need to be involved in order to receive it in a timely and effective manner), and once gathered – will typically require some cleaning or standardization before the various datasets can be cross-referenced and analyzed, since each local data set will be collected according to the relevant organization application’s own practices and focuses.
7. Growth rate
Finally, you need to consider not only your current data but the speed in which your data is growing or changing. If the data sources are frequently being updated, or new data sources are frequently being added, this could tax your hardware and software resources (as less advanced systems would need to re-ingest the entire dataset from scratch whenever significant changes are made to the source data), as well as multiply the above mentioned issues around structure, type, size, etc.
So, where should you go from here?
If you identify with one or more of the above and think your data might just be complex, don’t despair: understanding is the first step towards finding an appropriate solution, and analyzing complex data doesn’t have to be overly complicated in itself.
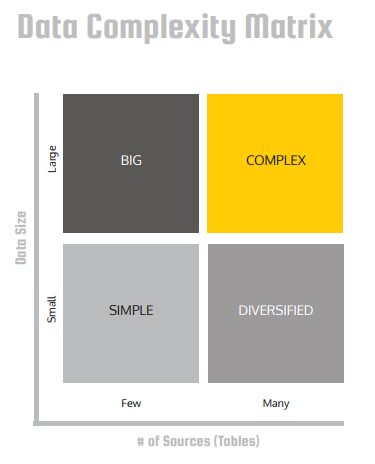
If you take a look at the data complexity quadrant to the right, you can classify your data according to the number of sources/tables and the size of the data. When looking for a BI solution, you need to consider which quadrant your data is in today and where it’s heading in the future. Once you’ve mapped your data, it’s time to look for a tool that will not only help you now but will be able to grow with your organization and your end users’ needs.
Look for a tool that is single stack and will allow you to do everything you need by unifying the business analytics process into a single software solution eliminating much of the ETL process and greatly simplifying what is left.
We might be biased but Sisense simplifies business analytics by reducing reliance on scarce, specialized IT skills and empowering individual business users. Business analysts can go from nothing to a fully functional business analytics program using production data in 90 minutes, delivering the fastest time to insight in the market.



