Getting started with Data Analysis in Python after using SQL
- Blog
- Tech Talk
SQL is the dominant language for data analysis because most of the time, the data you’re analyzing is stored in a database. And most analysis involves a lot of filtering, grouping, and counting — actions that SQL makes very easy….
SQL is the dominant language for data analysis because most of the time, the data you’re analyzing is stored in a database. And most analysis involves a lot of filtering, grouping, and counting — actions that SQL makes very easy.
But sometimes you need to go beyond pure SQL. Some analyses require complex business logic or advanced statistics. While you can do advanced statistics in pure SQL, it’s often a lot simpler to use Python.
This post is about starting that transition. If you’re already comfortable with SQL, and want to get started with Python, this is a look into some of the valuable transformations you can build. We’ll look at how to calculate linear regressions using Python, after using SQL to create our dataset.
We’ll use a sample video game database and uncover the relationship between how many times frequent players play the game, and how much money they spend in-game.
Generating the dataset: Gameplays vs. spend
The database has a gameplays table, with one row for every time a player plays the game. Our first CTE will generate [user_id, num_plays]:
with
user_plays as (
select
user_id
, count(1) as num_plays
from
gameplays
group by
1
)The database also has a purchases table, with one row for every purchase. The second CTE will generate [user_id, total_spent]:
, user_spend as (
select
user_id
, sum(price) as total_spent
from
purchases
group by
1
)Now we’ll join those two CTEs together, making the dataset we’ll use for our first correlation [num_plays, total_spent]. We’ll restrict the dataset to players who have played at least 150 games to focus on frequent players:
select
num_plays
, total_spent
from
user_plays
join user_spend using (user_id)
Where
num_plays > 150The output looks like this:

The Hello World of linear regressions in Python
There are many Python libraries that help with data analysis. We’ll start with seaborn and use the easiest way to make a linear regression, a jointplot. As a bonus, this plot type also comes with histograms.
Just import seaborn and pass the data frame generated from the SQL query to jointplot:
import pandas as pd
import seaborn as sns
sns.jointplot(x='num_plays', y='total_spent', data=df, kind='reg')Which generates our linear regression:

Easy! As we could have predicted, players who play more also spend more, in general.
However, scatter plots aren’t the right plot type to show dense clusters of information since they hide density — many data points could be hidden behind a single dot. In these cases, hex binning can tell the data’s story more effectively.
With hex binning, the plot area is divided into equally sized hexagons, and the color shading of each hexagon is based on how many data points fall within that hexagon’s boundaries.
Why hexagons and not another shape? There are three regular shapes that can tessellate, or cover a surface without gaps or overlaps, in 2D plots. Squares and triangles are the other two. Hexagons are generally preferred for binning because they are closest to a circle (compared to triangles and squares). Circles are most representative of a “bin” because circles have the minimum distance between their borders and the center point among 2D shapes, which minimizes outliers in the bin.
With seaborn, it’s easy to change from a scatter jointplot to one that uses hex binning. Simply change, the kind parameter to ‘hex’. While we’re changing things, let’s also change the color from blue to magenta with color=’m’:
sns.jointplot(x='num_plays', y='total_spent', data=df, kind='hex', color='m')Making our new plot look like this:

With this plot type, it’s easy to see where the density of data points varies, which we couldn’t tell from the scatter above.
Segmenting Our Dataset into Multiple PlotsThis video game is multi-platform, so let’s use Python to make a separate linear regression for each platform: Web, Android and iOS. First, we’ll update our query to include platform, in both CTEs and in the outputted data:
with
user_plays as (
select
user_id
, platform
, count(1) as num_plays
from
gameplays
group by
1
, 2
)
, user_spend as (
select
user_id
, platform
, sum(price) as total_spent
from
purchases
group by
1
, 2
)
select
num_plays
, total_spent
, platform
from
user_plays
join user_spend using (user_id, platform)
where
num_plays > 150Which has this output:
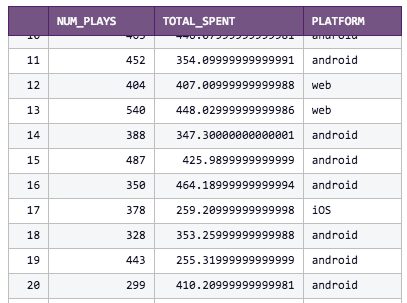
And, still using seaborn, we’ll switch from jointplot to lmplot. The lmplot function makes it easy for us to make one plot for each of our platforms. We no longer need the kind argument, instead we pass in the column to segment by, col=’platform’, and also tell lmplot to make each platform a different color using hue=’platform’:
sns.lmplot(x='num_plays', y='total_spent', data=df, col='platform', hue='platform')We’ve created three plots at once:

Segmenting out the data was informative! Web and iOS players have very different play count and spend distributions.
Bonus lap: 3D scatter plots
Sometimes it’s helpful to plot a third variable to shed more light on the distribution. In our case, we’ll include the number of purchases a player has made to tease out if we’re looking at few large purchases vs. many small purchases. In the user_spend CTE we’ll add count(1) as num_purchases to the select clause and include that column in the final SQL output as well.
For 3D scatters, we will use matplotlib instead of seaborn. First, we’ll import the library and set up the 3D context:
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
ax = plt.figure().add_subplot(111, projection='3d')Unlike seaborn, matplotlib won’t auto-color the different platforms for us. So we’ll add a new column to our dataframe that maps Android to orange, Web to blue and iOS to green:
df['colors'] = df['platform'].replace({ 'android': 'orange', 'web': 'b', 'iOS': 'g'})And now for the fun part, making the 3D scatter! Seaborn’s arguments were column names and the whole data frame. With matplotlib, we pass in each column whole (as x, y then z) and a fourth parameter sets the colors. After, we’ll label the axes:
ax.scatter(df['num_plays'], df['total_spent'], df['num_purchases'], c=df['colors'])
ax.set_xlabel('Number of Plays')
ax.set_ylabel('Total Spent')
ax.set_zlabel('Number of Purchases')Running this generates our 3D scatter plot:

While they look neat, 3D plots are often useless if they aren’t part of an animation or have some way of letting users move the perspective. Without that, a 2D rendering of a 3D plot can make it very difficult to see where the points actually are in the space.
Onward!
With just a few lines of Python, it’s easy to build on your SQL expertise to generate analyses that benefit from advanced statistics, especially when those statistics are inconvenient to calculate in SQL. Another benefit of using Python to visualize statistics is that you’re not tied to whatever built-in visualizations are available in your SQL environment.
Of course, this is just the beginning. Python makes it easy to include complex business logic, more advanced statistics or more advanced visualizations. Sisense for Cloud Data Teams supports dozens of R and Python libraries made for data analysis and visualization, ready and waiting for your next data project!



