SQL Query Order of Execution
- Blog
- Builder Education
- SQL Superstar
- Tech Talk
- Unlock Complex Data
The SQL order of execution defines the order in which the clauses of a query are evaluated. Understanding query order can help you optimize your queries.
SQL is one of the analyst’s most powerful tools. In SQL Superstar, we give you actionable advice to help you get the most out of this versatile language and create beautiful, effective queries.
Creating order
The steps you take in order to accomplish a goal matter! When you’re baking a cake, you have to preheat the over, grease the pan, and mix the ingredients in the proper order or else you’re going to end up with a mess instead of a delicious treat. Picking the right SQL order of operations is also important if you want to run efficient, effective queries. This article will take you through some best practices to get you started on optimizing your SQL query order.
Defining SQL order of execution
The SQL order of execution defines the order in which the clauses of a query are evaluated. Some of the most common query challenges people run into could be easily avoided with a clearer understanding of the SQL order of execution, sometimes called the SQL order of operations. Understanding SQL query order can help you diagnose why a query won’t run, and even more frequently will help you optimize your queries to run faster.
In the modern world, SQL query planners can do all sorts of tricks to make queries run more efficiently, but they must always reach the same final answer as a query that is executed per the standard SQL order of execution. This order is:
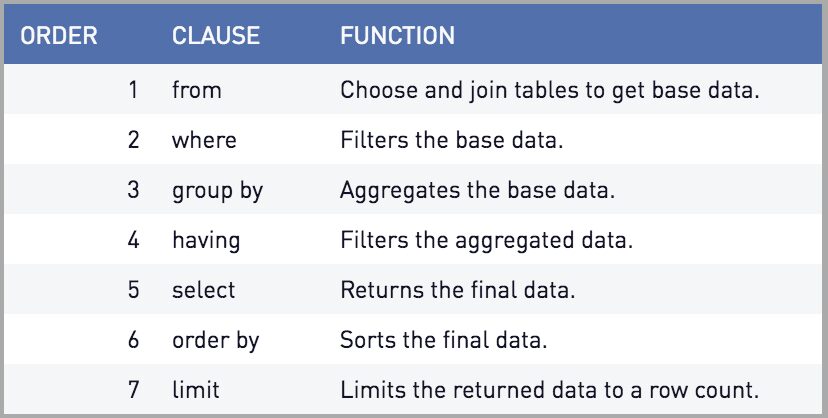
FROM clause
SQL’s from clause selects and joins your tables and is the first executed part of a query. This means that in queries with joins, the join is the first thing to happen.
It’s a good practice to limit or pre-aggregate tables before potentially large joins, which can otherwise be very memory intensive. Many modern SQL planners use logic and different types of joins to help optimize for different queries, which can be helpful but shouldn’t be relied on.
In an instance like below, the SQL planner may know to pre-filter pings. That technically violates the correct SQL query order, but will return the correct result.
select
count(*)
from
pings
join
signups
on
pings.cookie = signups.cookie
where
pings.url ilike '%/blog%'However, if you are going to use columns in a way that prevents pre-filtering, the database will have to sort and join both full tables. For example, the following query requires a column from each table and will be forced into a join before any filtering takes place.
-- || is used for concatenation
select
count(*)
from
first_names
join last_names
on first_names.id = last_names.id
where
first_names.name || last_names.name ilike '%a%'To speed up the query, you can pre-filter names with “a” in them:
with limited_first_names as (
select
*
from
first_names
where
name ilike '%a%'
)
, limited_last_names as (
select
*
from
last_names
where
name ilike '%a%'
)
select
count(*)
from
limited_first_names
join
limited_last_names
on
limited_last_names.id = limited_first_names.idTo learn more, you can also read about how we sped up our own queries by 50x using pre-aggregation.
WHERE clause
The where clause is used to limit the now-joined data by the values in your table’s columns. This can be used with any data type, including numbers, strings, or dates.
where nmbr > 5;
where strng = 'Skywalker';
where dte = '2017-01-01';One frequent “gotcha” in SQL is trying to use a where statement to filter aggregations, which will violate SQL order of execution rules. This is because when the where statement is being evaluated, the “group by” statement has yet to be executed and aggregate values are unknown. Thus, the following query will fail:
select
country
, sum(area)
from
countries
where
sum(area) > 1000
group by
1But it can be solved using the having clause, explained below.
GROUP BY Clause
Group by collapses fields of the result set into their distinct values. This clause is used with aggregations such as sum() or count() to show one value per grouped field or combination of fields.
When using group by: Group by X means put all those with the same value for X in the same row. Group by X, Y put all those with the same values for both X and Y in the same row.
The group by clause is worthy of its own post for many reasons, and you can find a lot more information about “group by” in other posts on our blog or in our whitepaper about SQL query order tips and a wide array of other tricks and best practices.
Chris Meier is a Manager of Analytics Engineering for Sisense and boasts 8 years in the data and analytics field, having worked at Ernst & Young and Soldsie. He’s passionate about building modern data stacks that unlock transformational insights for businesses.



