Use subqueries to count distinct 50X faster
- Blog
- Tech Talk
NB: These techniques are universal, but for syntax we chose Postgres. Thanks to the inimitable pgAdminIII for the Explain graphics. So useful, yet so slow Count distinct is the bane of SQL analysts, so it was an obvious choice for…
NB: These techniques are universal, but for syntax we chose Postgres. Thanks to the inimitable pgAdminIII for the Explain graphics.
So useful, yet so slow
Count distinct is the bane of SQL analysts, so it was an obvious choice for our first blog post.
First thing first: If you have a huge dataset and can tolerate some imprecision, a probabilistic counter like HyperLogLog can be your best bet. For a quick, precise answer, some simple subqueries can save you a lot of time.
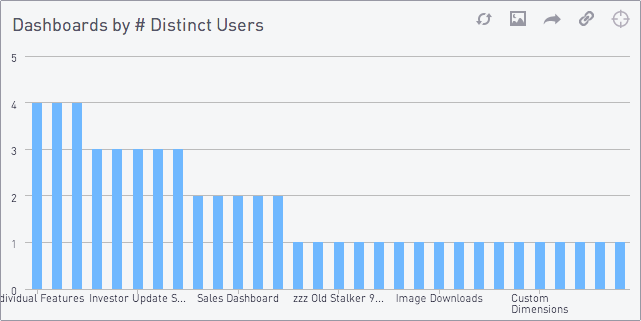
Let’s start with a simple query we run all the time: Which dashboards do most users visit?
select
dashboards.name,
count(distinct time_on_site_logs.user_id)
from time_on_site_logs
join dashboards on time_on_site_logs.dashboard_id = dashboards.id
group by name
order by count descThis returns a graph like this:
For starters, let’s assume the handy indices on user_id and dashboard_id are in place, and there are lots more log lines than dashboards and users.
On just 10 million rows, this query takes 48 seconds. To understand why, let’s consult our handy SQL explain:
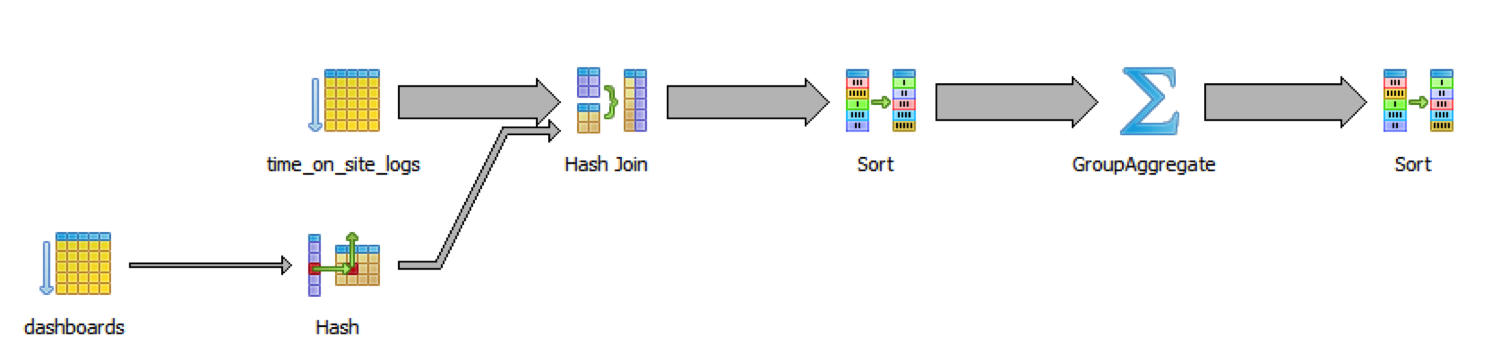
It’s slow because the database is iterating over all the logs and all the dashboards, then joining them, then sorting them, all before getting down to real work of grouping and aggregating.
Become an instant SQL expert:
Aggregate, then join
Anything after the group-and-aggregate is going to be a lot cheaper because the data size is much smaller. Since we don’t need dashboards.name in the group-and-aggregate, we can have the database do the aggregation first, before the join:
select
dashboards.name,
log_counts.ct
from dashboards
join (
select
dashboard_id,
count(distinct user_id) as ct
from time_on_site_logs
group by dashboard_id
) as log_counts
on log_counts.dashboard_id = dashboards.id
order by log_counts.ct descThis query runs in 20 seconds, a 2.4X improvement! Once again, our trusty explain will show us why:

As promised, our group-and-aggregate comes before the join. And, as a bonus, we can take advantage of the index on the time_on_site_logs table.
First, reduce the dataset
We can do better. By doing the group-and-aggregate over the whole logs table, we made our database process a lot of data unnecessarily. Count distinct builds a hash set for each group — in this case, each dashboard_id — to keep track of which values have been seen in which buckets.
Instead of doing all that work, we can compute the distincts in advance, which only needs one hash set. Then we do a simple aggregation over all of them.
select
dashboards.name,
log_counts.ct
from dashboards
join (
select distinct_logs.dashboard_id,
count(1) as ct
from (
select distinct dashboard_id, user_id
from time_on_site_logs
) as distinct_logs
group by distinct_logs.dashboard_id
) as log_counts
on log_counts.dashboard_id = dashboards.id
order by log_counts.ct descWe’ve taken the inner count-distinct-and-group and broken it up into two pieces. The inner piece computes distinct (dashboard_id, user_id) pairs. The second piece runs a simple, speedy group-and-count over them. As always, the join is last.

And now for the big reveal: This sucker takes 0.7 seconds! That’s a 28X increase over the previous query, and a 68X increase over the original query.
As always, data size and shape matters a lot. These examples benefit a lot from a relatively low cardinality. There are a small number of distinct (user_id, dashboard_id) pairs compared to the total amount of data. The more unique pairs there are — the more data rows are unique snowflakes that must be grouped and counted — the less free lunch there will be.
Next time count distinct is taking all day, try a few subqueries to lighten the load.
Become an instant SQL expert:



